Analysis of Machine Learning and Computer Vision Emphasizing Unified Ant Colony Optimization
Noah M. Kenney
Abstract
Through this paper, we analyze specific branches of Artificial Intelligence (AI) technologies, such as Machine Learning (ML) and Computer Vision (CV). Specifically, we explore synergies between ML and CV, highlighting how Unified Ant Colony Optimization (ACO) serves as a unifying optimization technique in addressing complex problems within these domains. We also delve into the intricacies of ML and CV, examining both their theoretical foundations and practical applications, before exploring the Unified ACO algorithm and considering how it can be utilized to address difficult computational problems.
I. Introduction
The prevalence of artificial intelligence technologies like Machine Learning (ML) have gained popularity in applied sciences, such as medicine and Computer Vision (CV). However, we pose the question of whether artificial intelligence has a consciousness and how it would change the state of the matter if it was proven that an AI was conscious, although it is not possible to prove. It is first possible to estimate that network of neural nodes cannot produce a conscious mind that mimics the neurons or cognitive ability possessed by the human brain. We address this question for further investigation from psychological point of view with the main focus on cognitive abilities of the artificial intelligence which cannot be achieved by simply simulating the neural network, regardless of computational power.
Artificial Intelligence (AI) and its consciousness is a general question of the modern Computer Science, which is highlighted in the press by many researchers [1, 2]. We seek to answer the question whether it is important and whether it is possible. First, we give our argument towards the fact that psychology and self “I” of any mind cannot be followed from the chaos produced by the neural network, thus, all the arguments made towards the fact that AI can be conscious based upon latest knowledge and technology cannot be addressed to the main point of view as per analogy of the human “I” and his or her modus operandi.
The data volume as a starting point of view are very big (hundreds of gigabytes of pure textual data) in order to train the neural network. This is a very challenging task as acquiring such a large amount of data and successful storage of the trained neural network necessitates investing in Big-Data hardware. Thus, Big Data for AI poses economic challenges, since many cloud-based services are offered on a “freemium” business model, which is not sustainable from an economic standpoint with high computational resource expenses.
Thus, beyond the theoretical possibility of creating an AI that is truly comparable to human consciousness, we find that it is not feasible (at least at present) for commercialization given the high costs of developing a sufficiently computationally advanced system. Additionally, we suggest that many AI and software engineers are disincentivized from creating an AI resembling consciousness, given that such an AI would be capable of replacing their job, leading to personal negative financial ramifications.
Further, we should consider whether there is considerable harm in creating an AI that resembles consciousness. It is possible to train the neural network against utilizing the prohibited type of data, and against allowing for users to submit harmful queries (in the case of LLMs). Thus, if we, for example, would train the network against the binary codes of executables and their source codes, this will lead to the reverse engineering which is a prohibited method of obtaining source codes of programs from their packaged content. The same malicious method can be applied to password brute force attacks and other tasks which involve the example to be selected from the large amount of sample data.
ChatGPT and other modern tools utilizing artificial intelligence are already beginning to implement the use automated assistants in business processes. This still poses economic considerations; however, due to the existing capabilities of the automated solutions, there’s no need for human oversight. Thus, the economic benefit or harm of proficient artificial intelligence systems remains an open question in the global labor market.
When considering the theoretical consciousness of AI, we turn our attention to psychological, psychical and physiological processes of the human brain. In these processes, signals are transferred through interconnected neurons between points. However, even when neural networks simulate this signal transmission, they still fail to sufficiently mimic the human brain to a point where we could consider it conscious. Additionally, all our discussion thus far has suggested that consciousness is merely cognitive in nature, which we do not believe to be the case. We can look at these limitations through psychiatry, likening it to what we can call a “Freud conjecture.” This is to say that AI systems do not instinctively develop a sense of self of “I” in the way that humans are instinctively self-aware. As a result, even a computationally sufficient AI would not resemble consciousness.
Beyond AI consciousness, we give the definition of algorithm of Explainable Machine Learning in order to define the extensible role of the ML in the field of algorithmic approach rather than resorting to the classical approach of neural networks.
II. UNIFIED ANT COLONY OPTIMIZATION (ACO) OR SWARM OPTIMIZATION
The unified ACO can be represented by the following starting operation for two matrices:
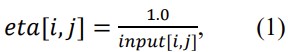
Where “eta” is a pheromone matrix and “input” is a matrix of the input data which are to be defined before the modeling ACO for optimization problem solution.
Another matrix which is to be defined as is:
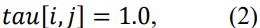
This is a compound matrix which defines the operation of each of the simulated agent like artificial ants.
During each iteration we define the next candidate to be chosen according to the following optimization function:
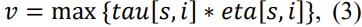
When the candidate v is chosen the matrix is updated according to the following rule:
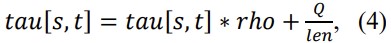
Where “rho” (between 0 and 1) and “Q” (between 0 and 100) are arbitrary parameters and “len” is the optimization function along the computed path of the selected candidates.
The universal approach of solving hard-problems without quantum computing or other means is the general acceptance method of the AI and solution of the so-called NP-hard or NP-complete problems which are also closed under EXPSPACE and EXPTIME.
The equations (1)-(4) are important to learn as they represent the inner output of the ACO algorithm in the main iteration which can be fixed or infinite and usually converges after pre-defined number of steps which is equal to the number of the size of the output.
To be clear, we stipulate that swarm optimization is a common term for ACO which is simpler to implement and our key result is to represent the unified form of this algorithm for further framework-like implementation which is already done in “AntTSP”-software package.
III. EXPLAINABLE MACHINE LEARNING
Modern tools of Machine Learning such as TensorFlow and imaginary detection is briefly discussed in [3]. The existing algorithms are described in [4] along with a neural network method. The use of Machine Learning in the present day within the practical experience is presented in [5] – this research states the question of the evaluation of Machine Learning in different types of application and its impact on the global stage. The modern usage of ML in wireless networks as the application is presented in [6].
After the overview of the research on the latest publications for Machine Learning and its application benefits and shortcomings, we present the algorithmically practical solution for ML, known as Explainable Machine Learning, or, simply, EML.
EML relies on input data and can be represented as the matrix of sorted elements by the category and priority at each row and column, the steps of building this matrix and evaluation of the query are defined as follows:
- Sort the input data matrix with given priority of each factor;
- Query the result for each data in the sorted matrix for the short-coming range of lower and upper row;
- For the number values do the floor or ceil of the value and compare it same way as the word entities in the input matrix.
Neural networks, which are based upon sigmoid functions, can be extended for EML as the algorithm for arbitrary function with respect to the term various probability type is well-known in modeling theory of mass-servicing queues.
The algorithm for arbitrary function f(x) is as follows:
- Define the function f(x) and its range L and R;
- Compute the minimum and maximum values of function f(x) on this range using differential calculus;
- Train the neural network by applying function f(x) divided by the minimum and maximum, with subtraction of the minimum.
The steps above give the novel example of the arbitrary learning without usage of sigmoid-function for neural network training.
IV. COMPUTER VISION
At present, the most well-known algorithms are for pattern string matching, i.e. the problem of finding the occurrences of pattern in the matching string. Examples would include Knuth-Morriss-Pratt and Boyer-Moore, both of which were adapted for the digital patterns, when patterns can be taken from the scanned image. We present the linear error-prune algorithm for OCR text matching.
The matching cost can be computed using a variety of techniques, such as Hamming distance. For experimental purposes, Tesseract OCR engine was used. However, the Hamming distance is good for low-cost computing, while the approach described in this paper can be used for large data. To handle the large data thread, we have used the windowing technique. Under this technique, the necessary data for the pre-defined time interval can be obtained as:
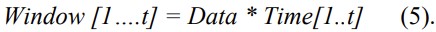
From the obtained data, the penalty can be computed. This penalty is the measure of equivalence between searching text and scrambled data, possibly by OCR engine. Thus, the following holds true:
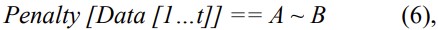
where: ‘A’ is the searching text and ‘B’ is scrambled data.
Now we would like to present a short introduction to the native approach. The naive approach is simple, as it only requires calculating the distance between two words. This method has practical applications when the number of symbols (or the weight of word) in text to be searched is small. By this method we get the magnitude equal to the weight of text. To compute this distance the bi-linear search is executed at every position in scrambled text. The cost here is, thus, a cumulative sum of penalties at every step when symbols coincide. This can be written as:
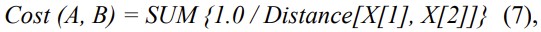
where: A, B are words and X[1], X[2] are positions of two consecutive matchings.
It should be noted that the algorithm experimentally produces good results for low-cost pattern (word A). Basic Java code can be utilized for this purpose.
The scalable window approach opposite to the native method uses flowing window event when the mismatching occurs: in other words, it slowly checks for occurrences of match in the appearing window. Thus, the possible result of excess symbols in scrambled text is reduced. The sub-algorithm decides what symbol will be gap’s left border, while the right border lies on the mismatched position [Y[1], Y[2]] (in pattern and scrambled text).
Example 1. Sample of scrambled text retrieved by Tesseract OCR

The algorithm uses input parameters for windowing algorithm. This set can be extended. One example of this would be by extending the textual model of the scrambled text. In this example the textual model is a scrambled text with excess symbols produced by the engine which are incorrect and are to be removed or replaced. The final reduction, which requires minimal steps or data manipulation, leads to the exact expected text extraction.
V. Conclusion
We have presented the modern results on the Machine Learning, which is named in this article as Explainable Machine Learning. We presented it as it is more relevant and does not require the neural network to be trained, reducing the time of development significantly. This is because the EML-decision tree can be expanded by online query, and it operates in linear time, with a query performance time of O(n) where n represents the number of factors in the data matrix of the input.
We have also concluded that Marco Dorigo’s swarm optimization is an artificial intelligence methodology in its unified variant, giving the opportunity to solve NP-complete problems in a reasonable amount of time and quadratic space.
The question of artificial intelligence and its consciousness as well as the global impact of it on economics and the global labor market are questions which we pose, but acknowledge further research and data are needed on.
First Author: Noah M. Kenney
Second Author: Mirzakhmet Syzdykov
REFERENCES
[2] Hildt, Elisabeth “Artificial Intelligence: Does Consciousness Matter?” // https://www.frontiersin.org/articles/10.3389/fpsyg.2019.01535/full (accessed 3/30/2023).
[3] Jordan, Michael I., and Tom M. Mitchell. "Machine learning: Trends, perspectives, and prospects." Science 349.6245 (2015): 255-260.
[4] Mahesh, Batta. "Machine learning algorithms-a review." International Journal of Science and Research (IJSR). 9 (2020): 381-386.
[5] Athey, Susan. "The impact of machine learning on economics." The economics of artificial intelligence: An agenda. University of Chicago Press, 2018. 507-547.
[6] Chen, Mingzhe, et al. "Artificial neural networks-based machine learning for wireless networks: A tutorial." IEEE Communications Surveys & Tutorials 21.4 (2019): 3039-3071.